
The Era of
Provable Software
by Elena Burger and Kshitij Kulkarni
January 9th, 2025

New technologies have taken a remarkably consistent path on the way to widespread adoption. First, the technology is found in an embryonic, application-specific state. It is useful for a few specific tasks, but remains short of a general-purpose architecture that anyone can develop upon. Motivated by the search for a set of standards that provide developers with a framework on which to reliably build, a series of high-stakes ideological battles erupts among engineers and researchers. These debates lead to standardization and the possibility of scaling the technology. Application development and infrastructure build-outs intensify, leading to broad usage. We've seen this trend manifest in many eras since the early Internet, in technologies ranging from TCP/IP to artificial intelligence.
We are now entering a new era of the Internet: the era of provable software. Thanks to advancements in zero-knowledge (ZK) cryptography over the past decade, it is now possible to verify the execution of arbitrary statements that can be written as programs via general-purpose ZK virtual machines (zkVMs). Provable software unlocks a new class of applications in blockchains and computing more generally: with verifiable code, we can enable the trustless delegation of any computational task. This has wide-ranging implications for how we construct decentralized protocols, work with user identity and authentication, and architect business logic.
Reflecting on the history of technology gives us insights into the trajectory that provable software will take as it is widely integrated into the world. ZK began as highly application-specific; early programs needed to be encoded in circuits that could only be used for single applications. Today, with zkVMs like SP1, we are more confident than ever that provable software has found its general-purpose solution. Earlier this year, we released our plan for the Succinct Network, which introduces an infrastructure and financial incentive layer for the provisioning of ZK proofs, codesigned with SP1. We believe that the combination of SP1 and the Succinct Network are the right general purpose scaling solution for provable software.
In this essay, we lay out our main thesis: the transition from application-specific systems to general-purpose standards has catalyzed an infrastructure buildout in every previous era of software, and will do so again in provable software. Drawing from examples of transitions from applications-specific to general-purpose frameworks in the early Internet and AI (Figure 1), we see a unified history of software. This history gives us lessons for how the future of provable software will evolve.
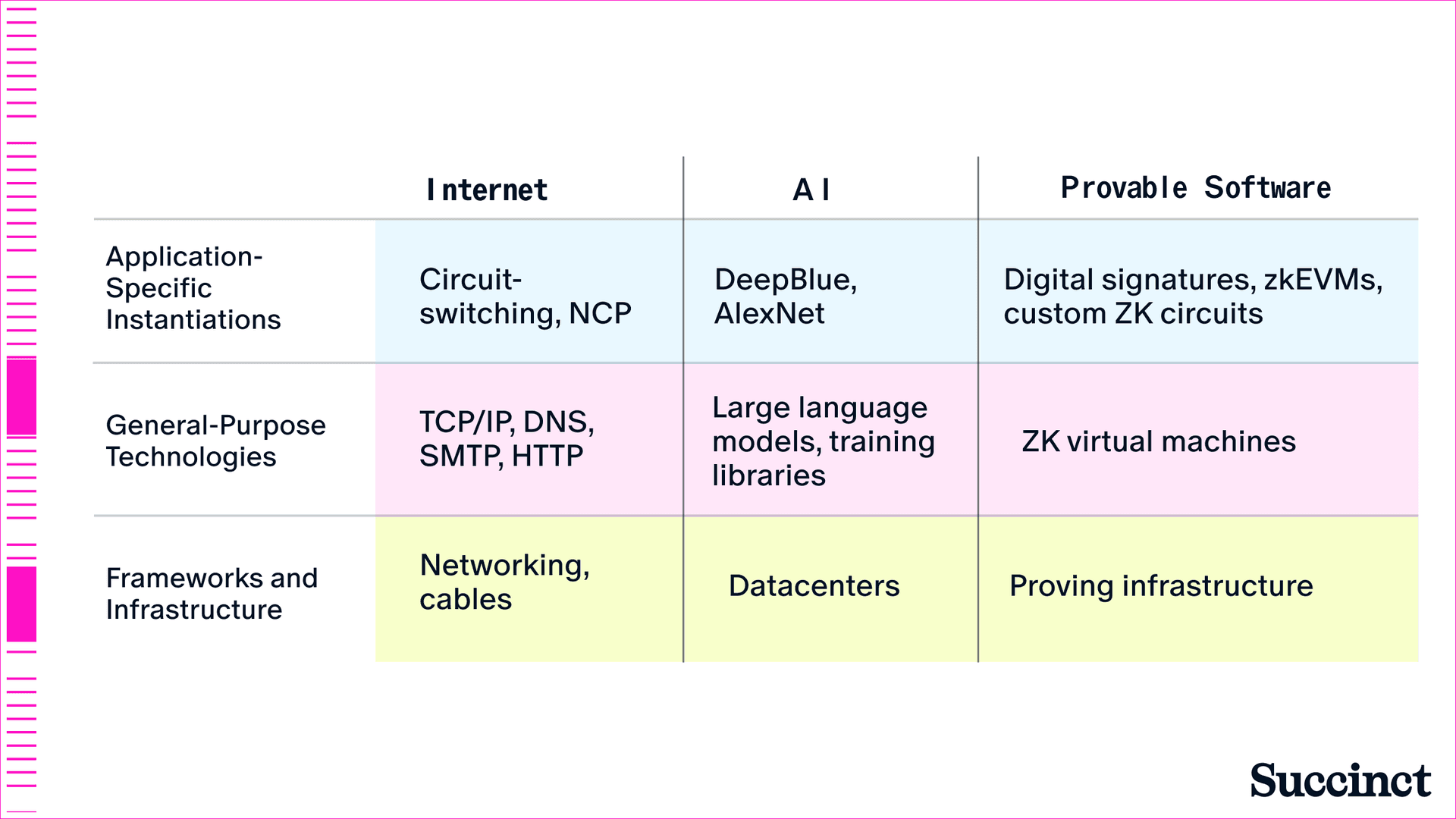
Figure 1: Comparison of the transition of software from application-specific to general-purpose.
Application-Specific Software
In this section, we cover the early, application-specific versions of the Internet, artificial intelligence, and cryptography.
The Early Internet: Application-Specific Packet Routing
In his book, Designing an Internet, David D. Clark outlines the standards that encode the packet-routing layer of the Internet: TCP/IP, which is a protocol that tells computer networks how information should be turned into packets and then transmitted over the network. Everything from consumer-grade routers to enterprise-level nodes implement TCP/IP, due to which applications on the Internet can handle a wide variety of data, from text, to images, to video, to games. Clark argues that the simplicity of these standards were vital in enabling this kind of widespread innovation. Prior to TCP/IP, a wide variety of competing standards created confusion and unwieldy developer fragmentation. In other words, without a simple, universal protocol ensuring the reliable delivery of data packets, it would have been impossible to achieve the general purpose applications we enjoy on the Internet today.
While TCP/IP is a simple protocol, it should not be taken for granted as the “winning” solution to worldwide Internet proliferation. From the 1960s until the 1990s, there were a variety of competing standards, all animated by different research initiatives and market forces. “Circuit-switching,” for example, was presented as an early rival to packet-switching, and advanced the idea of using telephone line network capacity to transmit data. This approach was fundamentally application-specific, and never took off as a result, because you'd have to allocate specific capacity to individual applications.
Even early packet switching was application-specific. In the late 1960’s, the U.S. Department of Defense developed ARPAnet using a packet-switching protocol known as NCP (Network Control Protocol). NCP had severe limitations compared to TCP/IP. For one, NCP couldn't automatically route around failed network links, which was acceptable given the small number of connected nodes, but would obviously face challenges when scaling.
Perhaps the biggest limitation of all was the tight coupling between the “software” layer of NCP and the applications it hosted. While ARPAnet did support early Internet applications like email, it was tightly coupled with the NCP protocol. Users would call “SNDMSG” to send an email and “READMAIL” to read one – and the system required both users to be online simultaneously. Email was essentially “in-protocol”.
In short, the earliest attempts at the Internet were application-specific: the NCP protocol was developed with the sole purpose of connecting nodes on the ARPAnet, and the applications built on top of the network were all hard-coded into the NCP protocol itself. It took further research – and competition from other frameworks – for the TCP/IP standard to emerge.
Application-Specific Artificial Intelligence
The pursuit of a general-purpose framework for machine learning has been a north star for the field of computer science since Alan Turing. In his 1950 paper, Computing Machinery and Intelligence, Turing lays out the goals for an intelligent computer that could learn like a child through “experience,” rather than through explicit programming. But the early implementations of AI model training systems were application-specific and designed specifically for functions like speech recognition, chess, and image identification - a reflection of the computational and algorithmic limitations of the time.
Brute-force training and explicit programming was an early dominant model in machine learning. Deep Blue, for example, went through nearly a decade of development before successfully beating Garry Kasparov in chess in 1997. The first iteration of the chess engine developed by IBM in 1986 and 1987 was fueled by research into how to achieve better computational gate utilization and parallelize search, two functions key to improving the number of predicted positions, and therefore the performance, of a chess engine. By the time researchers released Deep Blue in 1997, they had arrived at a much more sophisticated architecture: their dataset featured over 700,000 chess grandmaster games. While the model architecture was “successful” in the sense that it prevailed over Kasparov in a chess match, it represented the limits of machine learning at the time: the model could not generalize, it could only play chess.
Other breakthroughs in machine learning followed in the next fifteen years, but all were limited by an application-specific approach. Early approaches to training neural nets on primitive tasks like digit recognition and speech recognition were bottlenecked by dataset sizes and limited hardware capabilities in training and running inference on models. AI went through a long period of incremental improvements on benchmarks, but no real breakthrough advancements.
In 2012, the release of AlexNet, a model trained to classify images from the ImageNet dataset was heralded as a major breakthrough in the field of model training for its approach to model architecture (a multi-layer convolutional neural network with 60 million parameters, which was large for the time) and approach to splitting model training across GPUs.
But like past examples, AlexNet was limited – while it was seen as a step forward in terms of model sophistication, it was only capable of image recognition and lacked the ability to perform any general task not specified by its architecture. Further research was required before the field could arrive at something approaching “generalized intelligence.”
Application-Specific Cryptography: From Signatures to SNARKs
As our third example of application-specific implementations of software predating general-purpose ones, we turn to cryptography. The first mainstream cryptographic protocols, digital signatures, were advanced in the 1970s. In their 1976 paper, New Directions in Cryptography, Whitfield Diffie and Martin Hellman proposed a public key signature scheme that satisfies security properties that remain key imperatives today: the system must be reliably able to guarantee privacy and authentication (on behalf of the message signer) and be computationally secure to the degree that it can’t be brute-forced by an outsider seeking to forge a signature.
In 1978, the RSA signature scheme was proposed by Ronald Rivest, Adi Shamir and Leonard Adleman, which introduced a high-level algorithmic implementation of public-key cryptography, along with recommendations for the key’s signature length (given computational limits at the time, they estimated that their algorithm would take about 3.8 billion years to break). These systems solved three fundamental problems in cryptography: key exchange, encryption, and digital signatures.
Again, it’s important to note that these signatures were “application-specific” in their implementation and designed to solve specific cryptographic problems. Even as public-key signatures came to be integrated into the Internet (first in early forms, like implementations of RSA key exchange and authentication in 1990’s-era browsers like Netscape, and later throughout the Internet in signature schemes like ECDSA) they remained limited. The cryptographic signature schemes that rose to popularity along with the Internet were designed for one use case: securing and authenticating data on the Internet.
Up until recently in the Internet’s history, cryptography has been taken for granted as a security layer of the Internet, not a class of applications in its own right. While Bitcoin, Ethereum (along with scaling solutions for Ethereum), and other blockchains have productionized cryptography in the form of digital signatures, Merkle commitments, and zero-knowledge proofs for offchain verification and privacy, we’re still in the very early stages of provable software – which we believe is the general-purpose framework for cryptography.
Zero-knowledge proofs make cryptography programmable, making the leap from application-specific methods like digital signatures. However, even early implementations of zero-knowledge proofs have been application-specific. They have involved proving the correct execution of the Ethereum Virtual Machine, or designing proofs that only verify the output of a specific kind of application. These approaches are backwards-looking, leading to application-specific implementations of what should be a general-purpose technology.
Optimized, single-purpose ZK circuits required developer teams to work in silos, devising algorithms that were specific to their network and use-case. In this way, cryptography is reminiscent of the earliest era of the Internet, when there were a number of competing protocols that could not interoperate, or the early era of AI, when researchers pursued one-off implementations of training models before arriving at general-purpose deep-learning. But just like we’ve found and scaled general-purpose forms of those technologies, the general-purpose form of provable software is also imminent.
The Transition to General-Purpose Software
We now cover the inflection point that makes early technologies ready for widespread adoption: the search for a general-purpose solution. This solution typically comes as a programmable, standardized version of earlier implementations, and makes development dramatically easier.
The Early Internet: Standardization
In the 1970’s, researchers at ARPAnet began exploring ways to overcome the lack of interoperability imposed by NCP, and eventually arrived at the TCP/IP standard on which the Internet is built today. In 1983, ARPAnet officially transitioned to TCP/IP, and in 1989, ARPAnet was officially decommissioned and efforts transitioned into an organization known as NSFnet, which leveraged the interoperability of TCP/IP to begin connecting research organizations and other supercomputer centers.
In the 1980’s, DNS was implemented on top of TCP/IP to give users a way to register for a predetermined address on the Internet. Before that, users of the net would have to email one guy – Jon Postel at the Information Sciences Institute – in order to map their name to a domain address, an approach that of course could not scale. Other general application frameworks began to arise as well: SMTP, standardized in 1982, gave rise to modern-day email while HTTP, launched in 1991, gave rise to modern-day webpages.
It was only after TCP/IP was standardized that the app layer was able to truly take off (Figure 2). By the end of the 1990’s, the encapsulation of “data” that could be transmitted by packets continued to grow more expansive, from static text and email, to images, audio, voice, video, and games. By the year 2000, there were over 17 million websites and 413 million users online – a testament to the powerful standards that ensured the application layer could thrive.
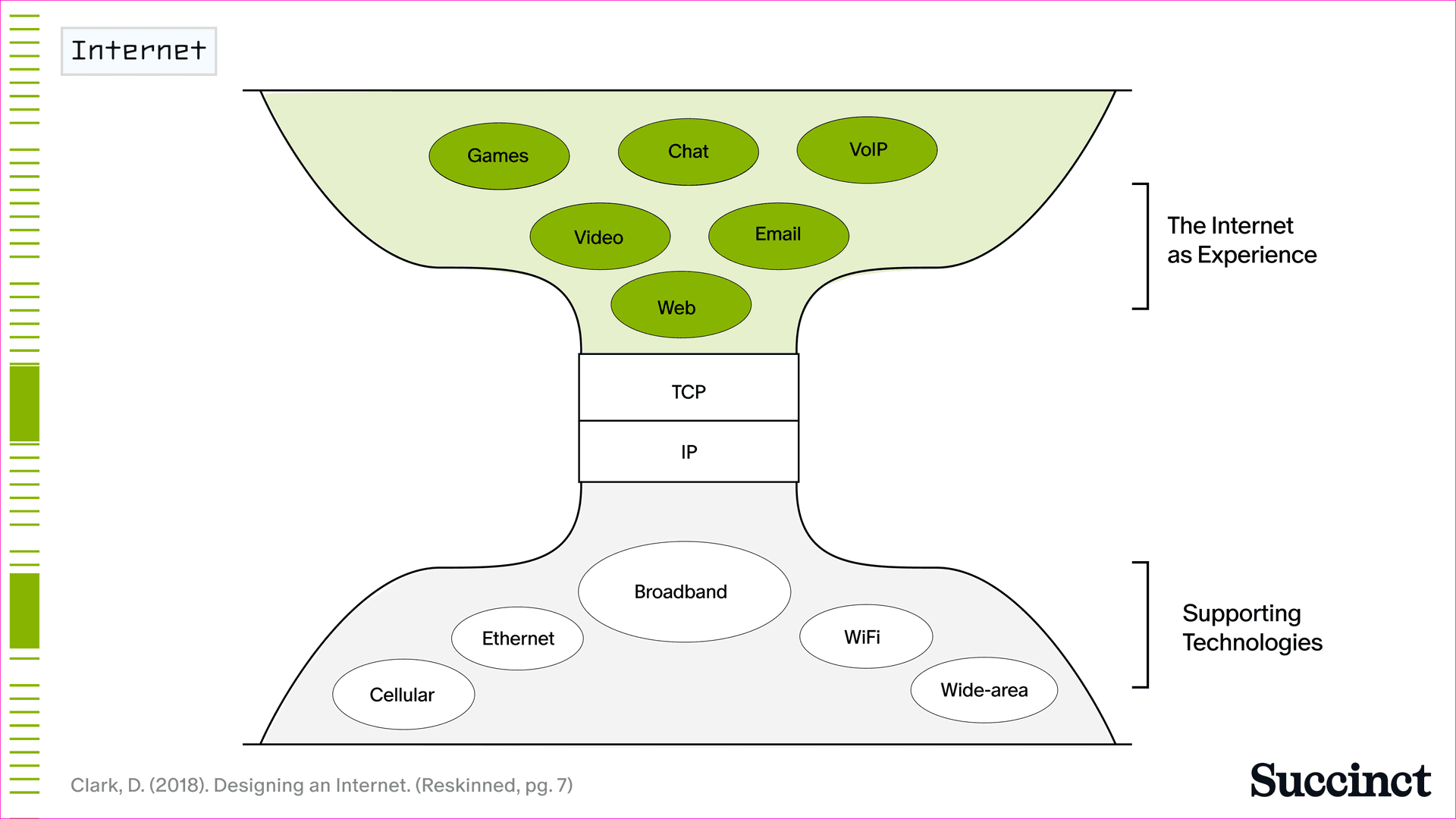
Figure 2: The Internet became standardized around TCP/IP, which enabled the application layer to flourish.
General-Purpose Artificial Intelligence
At this point in the AI adoption cycle, the scaling hypothesis is well-understood: deep-learning models get better when you combine high-quality and robust datasets with improved model architectures and scaled compute. But in order to reach this point, significant standardization at the software layer needed to occur.
In 2015, deep learning development reached a turning point when Google open-sourced TensorFlow, which became one of the most influential and widely-adopted general-purpose frameworks for training neural networks. TensorFlow standardized implementations of common operations: prior to its release, researchers had to implement backpropagation, gradient descent, and other fundamental algorithms from scratch. Pytorch, released by Meta in 2016, was another open-source model framework that brought the general-purpose training movement more mainstream. PyTorch introduced dynamic computational graphs that could be modified on the fly and allowed researchers to simply write Python code.
In 2017, Google released the now-renowned paper titled “Attention is All You Need”, which introduced a new abstraction layer for deep learning: the transformer. This invention led to more efficient training of models and easier parallelization of processes across GPUs and led to the development of large language models, which was a “generalized unit” of intelligence that operated simply on text sequences. GPT-2, which was released in 2019, represented a culmination of these learnings surrounding language model scale and implementation, and was notable for demonstrating that a language model trained on a broad dataset could perform various tasks without explicitly training for them.
Once it became clear that the combination of training libraries and transformer models could lead to large language models capable of the kind of generalized learning Alan Turing first articulated in 1950, a tremendous amount of energy was put into scaling this approach. GPT-2 had 1.5 billion parameters, which is insignificant compared to GPT-3 (175 billion parameters) and GPT-4 (estimated to be around 1.8 trillion parameters). Previously, one would have to train individual models to solve particular tasks, such as classification or translation. With GPT-3 and GPT-4, we had, for the first time, general-purpose models that made it possible to encode a vast number of tasks in a single architecture.
The abstraction layer for building generalized AI models means that today, anyone can build an AI application by leveraging APIs from transformer-based LLMs (not to mention the proliferation of open-source AI models from teams like Hugging Face and Meta). On top of this, everything from generative AI models, to coding assistants, to entire businesses are being built today (Figure 3).
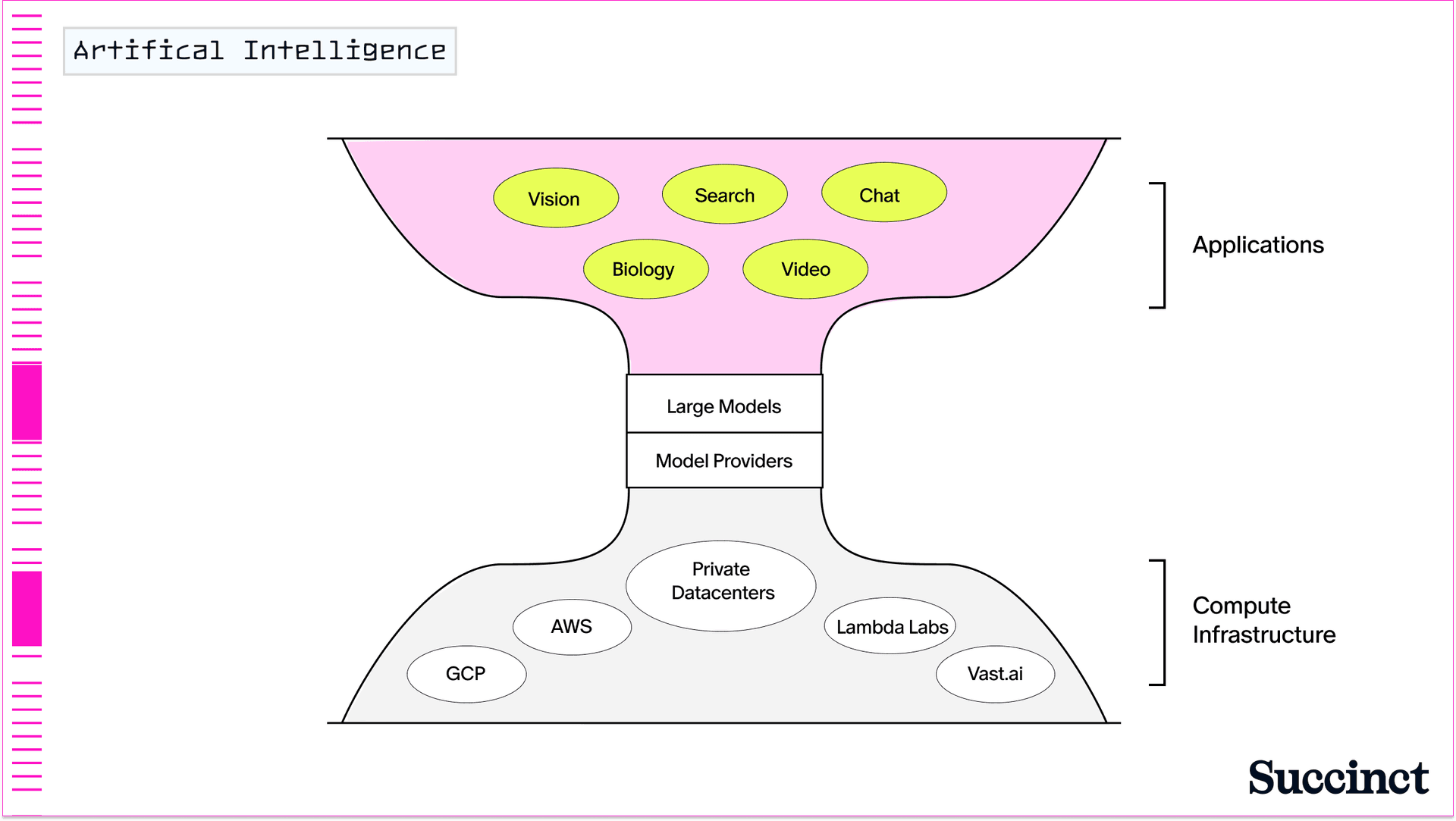
Figure 3: General purpose artificial intelligence.
The Road to General Purpose Provable Software
We’re now at a point where succinct proofs can be generated to prove any arbitrary computation. Earlier this year, we announced SP1, a zkVM that can prove not just rollup execution, but the correct execution of any application, enabling a much faster time to market for teams building rollups, bridges, coprocessors, privacy solutions, and more. In the way that TCP/IP is the generalized form of the Internet, and model training frameworks combined with transformer-based architectures led to generalized LLMs, zkVMs are the general-purpose form of provable software.
SP1 introduces a number of novel optimizations that make it ideal for proving software. It compiles down to RISC-V, an open-source instruction-set architecture popular in computing. It comes with common cryptographic precompiles, which decreases the RISC-V cycle count required for proof generation. And perhaps most importantly, it allows developers to write and verify any deterministic program in Rust, a massive unlock over less safe and expressive languages like Solidity.
In the last several months, we’ve seen a massive surge in the number of teams using SP1 as a general-purpose zkVM for provable software. It’s used by Taiko for proving mainnet blocks and rollup teams like Strata building on top of Bitcoin. Networks like Polygon use SP1 as the underlying proof system for Agglayer, its interoperability protocol. Succinct has also implemented a mechanism to replace OP Stack fault proofs with SP1 validity proofs, which will be adopted by Mantle, and is working with Celestia on a similar proof system for their network.
As we enter the era of provable software, we're witnessing standardization and the transition to general-purpose implementations unfold. We're moving from application-specific implementations of cryptographic protocols and zero-knowledge proofs (like those used in individual blockchain rollups) toward general-purpose proving systems that can handle any type of computation. Along with this, we will see infrastructure that standardizes around a proving system (Figure 4). We’ll discuss this in the next section.
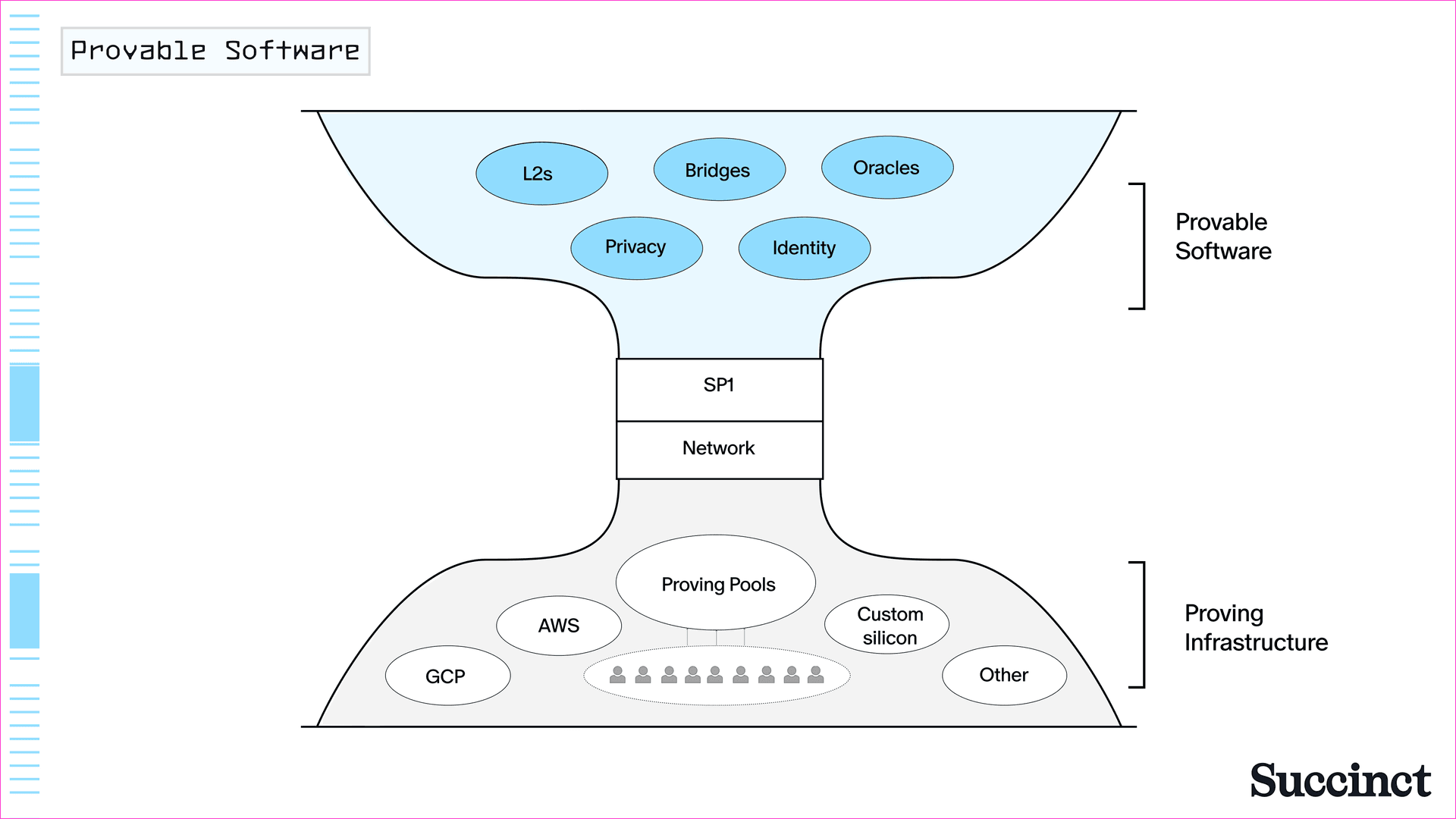
Figure 4: zkVMs like SP1 are the general-purpose form of provable software, enabling new applications.
Infrastructure Buildouts: Scaling Software
The transition to general-purpose software in all previous technologies is followed by corresponding infrastructure buildouts that enable applications to receive reliable, cost-effective services while serving the software to end users. History teaches us that this happened in the early Internet and in AI. We believe this trend will continue as provable software reaches widespread adoption.
Building out the Early Internet
Infrastructure build-outs have historically been accompanied with intense competition between their participants. From 1996 until the end of the dot-com bubble in 2000, AT&T, Sprint, and no-longer-existent ISPs like Worldcom, Level 3, Global Crossing spent at least $500 billion (roughly $934 billion adjusted for inflation) laying fiber-optic cables and building out wireless networks. TCP/IP's success validated what telecom executive David Isenberg called the "stupid network" philosophy - keep the core network simple and push intelligence to the edges. This influenced how telecoms approached their infrastructure investments, by allowing them to focus on laying lots of fiber and deploying simpler IP routers. This was especially relevant during the dot-com boom when speed of deployment was crucial.
Put differently, it took standardization at the software layer to allow the general-purpose application layer of the Internet to proliferate. After that happened, the operations layer of the Internet, in the form of network build-outs and predictable subscription-based pricing, became clear as well.
The AI Infrastructure Buildout
The trajectory of the AI model infrastructure buildout is similar. Researchers found a general purpose architecture for AI (LLMs) that could be simply attached to more compute, and this made scaling large language models predictable.
While authoritative and audited numbers are not publicly available on the amount of money model companies spend on build-outs, it’s possible to put together a picture of what spending outlay might look like. Chat-GPT cost over $100 million to train. Anthropic’s CEO has confirmed that a model that will cost $1 billion to train is underway. Mark Zuckerberg believes Meta will need 10x more computing power to train Llama 4 than Llama 3(which had 405 billion parameters). Since the beginning of 2024, NVIDIA’s revenue in its datacenter business, which includes sales of its GPUs, is over $79 billion – reflecting tremendous demand for both training and inference.
Other third-party infrastructure providers for on-demand training and inference have also emerged: companies like Lambda, Coreweave, not to mention cloud providers like AWS, GCP, and Azure all provide GPU renting services whose pricing models follow either an on-demand or reserved-capacity model. With the rise of test-time compute, or additional compute that is used when a model is queried, we expect to see even more infrastructure providers emerge to meet the demand.
The Infrastructure Buildout for Provable Software
Similarly, zkVMs will need their own “scaling hypothesis” to meet the demand already being expressed by rollup teams and other application builders. When most people in the world of blockchains think about “scaling”, they think about L1 and L2 performance. At Succinct, we think about scaling in terms of delivering a highly performant zkVM coupled with proving infrastructure that is censorship-resistant and resilient against downtime. We recently announced the Succinct Network, a new model for decentralized proving that leverages observations from infrastructure build-outs in past eras of software. The network recognizes the need for a coordinated infrastructure layer that allows competitive provers to meet proving throughput demand, and improve cost and performance for end users while generating proofs via SP1. Compared with other zkVMs, SP1 proofs are up to 10x cheaper to generate, giving potential GPUs and CPUs (not to mention other potential hardware implementations like FPGAs) on the network far better economies of scale.
We expect ZK proving infrastructure to follow a similar trajectory as other technologies in history, where a standardized, general-purpose solution is developed and then scaled with infrastructure. However, the build-out for proving will not look as top-down as previous infrastructure eras. Rather than a handful of ISPs and telcos, or distributed GPU datacenters run by a few large companies, we expect to see provers from across the ecosystem, from hardware teams to datacenter operators provide services that ultimately make the end user experience more valuable.
The Future of Provable Software
Looking back at previous eras, it is interesting to note that the application-specific implementations that were present in the earliest period of a technology could be re-implemented via their general purpose counterparts. Early, hardcoded email in the age of ARPAnet and the NCP protocol later became SMTP – a framework on which numerous email clients have been able to build. Early application-specific AI models are now the kinds of applications that can now be built on top of more generalized LLMs (e.g. you might see a chess-playing bot built on top of GPT-4). And early application-specific circuits for zkEVMs, bridging, identity, and more can now be implemented as applications built easily with SP1.
In addition to these architectural similarities throughout history, an even bigger point is clear: the Internet, AI, and provable software are all technologies with profound social implications. The Internet standardized around TCP/IP, which was capable of supporting a range of applications and hardware implementations. With the Internet, we got the instant transfer of data and information. AI standardized around training libraries and architectures that leveraged the fact that humans were transmitting and collecting massive amounts of data. We were able to turn the Internet’s data into knowledge and intelligence.
Today, the Internet is evolving and two forces are at play: the accelerating adoption of AI and the early glimpse of a world with provable software. Economies of scale advantage incumbents and lead to centralizing effects in AI. Provable software makes it possible to verify computation and intelligence without having to rely on trusted intermediaries. As intelligence becomes ubiquitous due to the scaling efforts of businessees around the world, it will be necessary to make all software provable. The technology that will make this future possible is here.